Import and log your dataset CSV file
This section shows how to import a dataset stored in a CSV file, convert it into a W&B Table, and store it in an artifact for reuse across runs. Use W&B artifacts to make the contents of the CSV file easier to reuse.- Import your CSV file. In the following code snippet, replace the
iris.csvfilename with the name of your CSV file:
- Convert the CSV file to a W&B Table to use with W&B Dashboards:
- Create a W&B artifact and add the table to the artifact:
- Start a new W&B run to track and log to W&B with
wandb.init():
wandb.init() API spawns a new background process to log data to a run, and it synchronizes data to wandb.ai by default. View live visualizations on your W&B Workspace Dashboard. The following image shows the output of the previous code snippet.
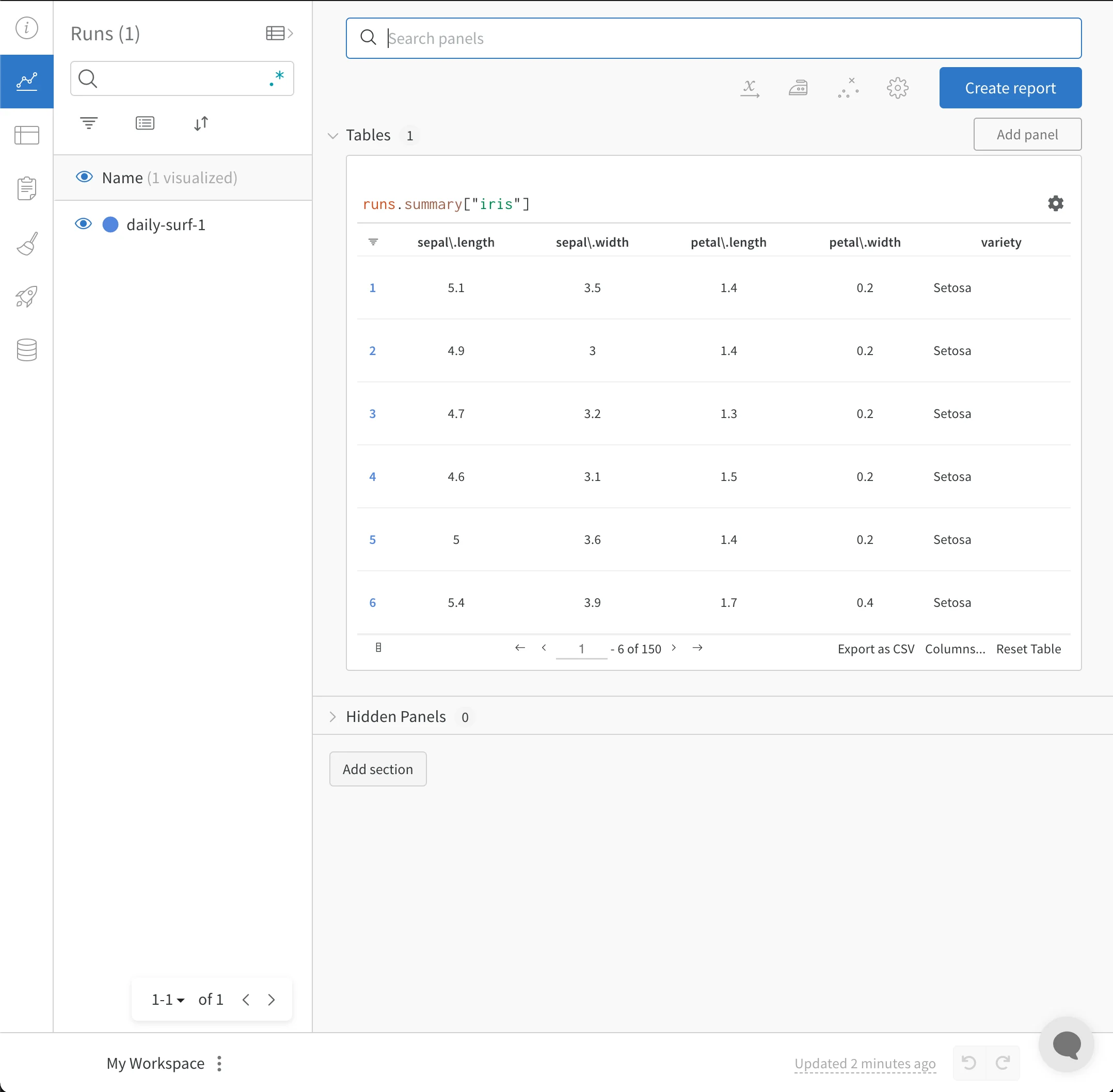
Import and log your CSV of experiments
This section shows how to take a CSV file that records past experiments and convert each row into a W&B run so you can visualize and compare them in a Dashboard. Sometimes, you might have your experiment details in a CSV file. Common details in such CSV files include:- A name for the experiment run.
- Initial notes.
- Tags to differentiate the experiments.
- Configurations needed for your experiment (with the added benefit of being able to use our Sweeps Hyperparameter Tuning).
| Experiment | Model Name | Notes | Tags | Num Layers | Final Train Acc | Final Val Acc | Training Losses |
|---|---|---|---|---|---|---|---|
| Experiment 1 | mnist-300-layers | Overfit way too much on training data | [latest] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 2 | mnist-250-layers | Current best model | [prod, best] | 250 | 0.95 | 0.96 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 3 | mnist-200-layers | Did worse than the baseline model. Need to debug | [debug] | 200 | 0.76 | 0.70 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| … | … | … | … | … | … | … | |
| Experiment N | mnist-X-layers | NOTES | … | … | … | … | […, …] |
- Read in your CSV file and convert it into a Pandas DataFrame. Replace
"experiments.csv"with the name of your CSV file:
-
Start a new W&B run to track and log to W&B with
wandb.init():
run.log() command:
define_metric API. This example adds the summary metrics to the run with run.summary.update():